
Solr Analyzers and Scoring




Dec 07, 2017



My previous blog post described how to configure and work with different query parameters for Solr using the SolrNet library. This post describes the concept of analyzers and filters in indexing, querying, scoring, and debugging the scoring mechanism. It's useful to see how the documents were scored and why one result is more relevant than the other. This will help you in understanding the indexing and querying aspects and debugging the scoring mechanism in Solr.
Solr Analyzers
This could be a simple analyzer that takes the field content and produces a token stream or more complex chaining of different Char Filters, Tokenizers, Token Filters. Analyzers determine what gets indexed and what gets queried.
Simple Analyzer
This is a white space analyzer that takes a text stream and breaks it into tokens on whitespace.
Simple Analyzer Example
<fieldType name="text_general"class="solr.TextField"positionIncrementGap="100">
<analyzerclass="org.apache.lucene.analysis.core.WhitespaceAnalyzer"/>
</fieldType>
Complex Analyzer
This is complex analyzer made up of char Filter, Tokenizer, and Filters. This has two analyzers configured, one for indexing and the other for querying. SynonymFilter was used during indexing, but not during querying. It is important to make sure that the analysis is done in similar way between indexing and querying to yield better results.
Complex Analyzer Example
<fieldType name=“text_general” class=“solr.TextField” positionIncrementGap=“100”>
<analyzer type=“index”>
<charFilter class=“solr.HTMLStripCharFilterFactory” />
<tokenizer class=“solr.WhitespaceTokenizerFactory” />
<filter class=“solr.LowerCaseFilterFactory” />
<filter class=“solr.WordDelimiterFilterFactory” splitOnNumerics=“0” splitOnCaseChange=“1” generateWordParts=“1” generateNumberParts=“1” catenateWords=“1” catenateNumbers=“1” catenateAll=“1” preserveOriginal=“1” />
<filter class=“solr.SynonymFilterFactory” synonyms=“syns.txt”/>
</analyzer>
<analyzer type=“query”>
<charFilter class=“solr.HTMLStripCharFilterFactory” />
<tokenizer class=“solr.WhitespaceTokenizerFactory” />
<filter class=“solr.LowerCaseFilterFactory” />
<filter class=“solr.WordDelimiterFilterFactory” splitOnNumerics=“0” splitOnCaseChange=“1” generateWordParts=“1” generateNumberParts=“1” catenateWords=“1” catenateNumbers=“1” catenateAll=“1” preserveOriginal=“1” />
</analyzer>
</fieldType>
Char Filter - This is the pre-processing component that can add/remove characters and change the text stream that is being fed into the Tokenizer.
Tokenizer - This component takes the text input stream and produces a token stream as output. The tokenizer is not aware of the field on which the analysis is being done. It is just operating at the text input stream.
TokenFilter - This component takes the token stream and produces a token stream as output. This can be applied either after Tokenizer, or chained with another TokenFilter.
You can look at how the analysis happens by going to the following page on your index:
http://localhost:8983/solr/#/car_search_index/analysisTo give an example, if you do the analysis in the provided techproducts solr example and search for "IPhone and I-Pod", you will see how the tokens are generated.
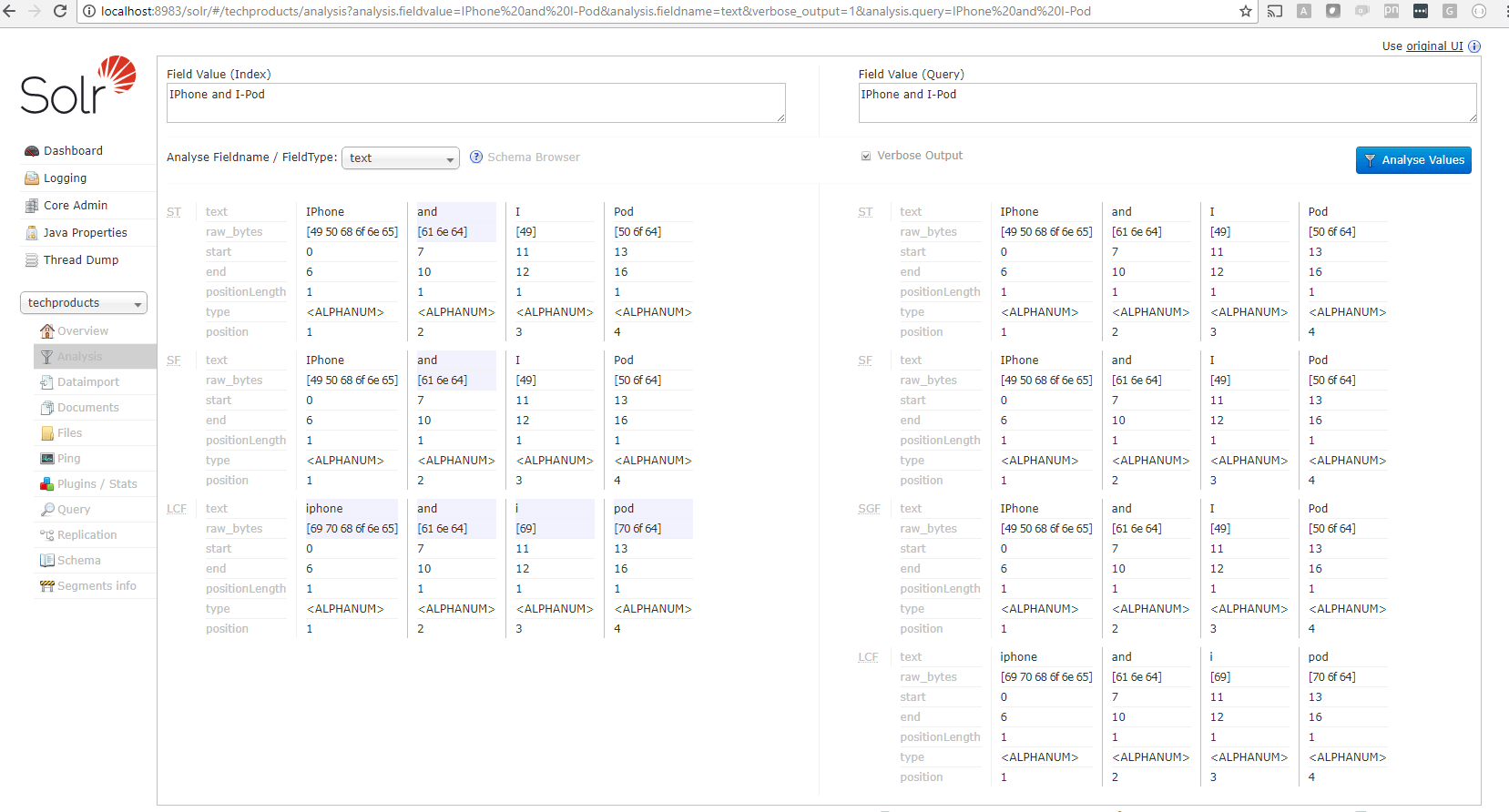
The corresponding fieldtype on this is text_general and is defined in the schema file as follow:
Search text analysis
<fieldType name=“text_general” class=“solr.TextField” positionIncrementGap=“100”>
<analyzer type=“index”>
<tokenizer class=“solr.StandardTokenizerFactory”/> <!— ST stage in the pic—>
<filter class=“solr.StopFilterFactory” ignoreCase=“true” words=“stopwords.txt” /> <!— SF stage in the pic —>
<filter class=“solr.LowerCaseFilterFactory”/> <!— LCF stage in the pic —>
</analyzer>
<analyzer type=“query”>
<tokenizer class=“solr.StandardTokenizerFactory”/> <!— ST stage in the pic —>
<filter class=“solr.StopFilterFactory” ignoreCase=“true” words=“stopwords.txt” /> <!— SF stage in the pic —>
<filter class=“solr.SynonymGraphFilterFactory” synonyms=“synonyms.txt” ignoreCase=“true” expand=“true”/> <!— SGF stage in the pic —>
<filter class=“solr.LowerCaseFilterFactory”/> <!— LCF stage in the pic —>
</analyzer>
</fieldType>
If this is not how your field text should be tokenized, then you can take a look at the other tokenizers such as ClassicTokenizer, N-Gram Tokenizer and evaluate if the text is tokenized the way you want it.
Scoring
Default scoring in Solr uses the TF-IDF algorithm. Often, we would like to know why one result item is better than other. In such cases, Solr helps us to understand how it determined those results and provides the score calculation. In order to see this, we need to turn on the additional parameter &debugQuery=on and it would show an additional "explain" section in the returned response that shows the calculations Solr did in order to come to that decision. For example, searching for GB in techproducts example is as follow:
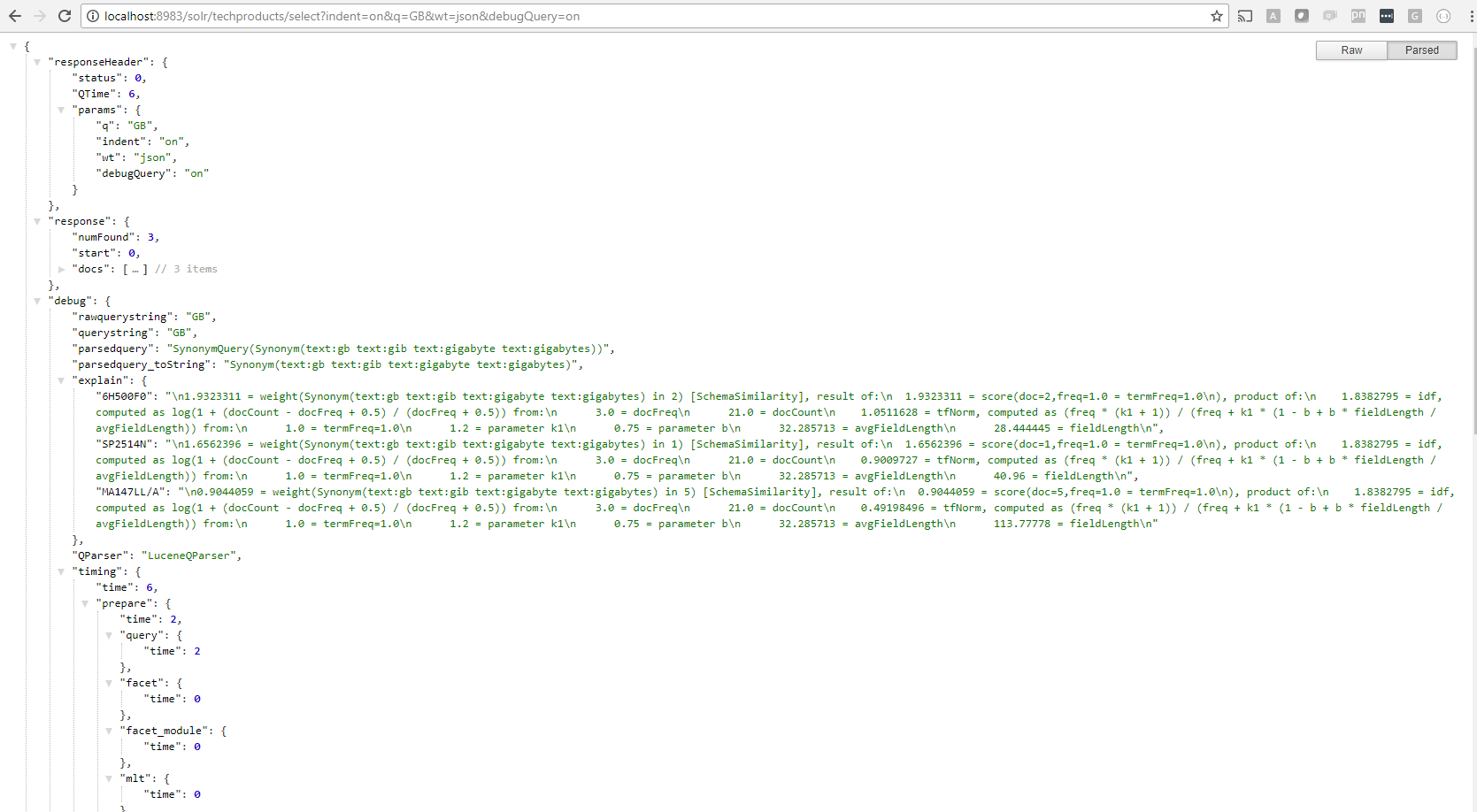
Taking these records and grouping to see how it calculates:
Scoring calculation
“6H500F0”:
1.9323311 = weight(Synonym(text:gb text:gib text:gigabyte text:gigabytes) in 2) [SchemaSimilarity], result of:
1.9323311 = score(doc=2,freq=1.0 = termFreq=1.0), product of:
1.8382795 = idf, computed as log(1 + (docCount - docFreq + 0.5) / (docFreq + 0.5))
from: 3.0 = docFreq 21.0 = docCount
1.0511628 = tfNorm, computed as (freq * (k1 + 1)) / (freq + k1 * (1 - b + b * fieldLength / avgFieldLength))
from: 1.0 = termFreq=1.0 1.2 = parameter k1 0.75 = parameter b 32.285713 = avgFieldLength 28.444445 = fieldLength
“SP2514N”:
1.6562396 = weight(Synonym(text:gb text:gib text:gigabyte text:gigabytes) in 1) [SchemaSimilarity], result of:
1.6562396 = score(doc=1,freq=1.0 = termFreq=1.0), product of:
1.8382795 = idf, computed as log(1 + (docCount - docFreq + 0.5) / (docFreq + 0.5))
from: 3.0 = docFreq 21.0 = docCount
0.9009727 = tfNorm, computed as (freq * (k1 + 1)) / (freq + k1 * (1 - b + b * fieldLength / avgFieldLength))
from: 1.0 = termFreq=1.0 1.2 = parameter k1 0.75 = parameter b 32.285713 = avgFieldLength 40.96 = fieldLength
“MA147LL/A”:
0.9044059 = weight(Synonym(text:gb text:gib text:gigabyte text:gigabytes) in 5) [SchemaSimilarity], result of:
0.9044059 = score(doc=5,freq=1.0 = termFreq=1.0), product of:
1.8382795 = idf, computed as log(1 + (docCount - docFreq + 0.5) / (docFreq + 0.5))
from: 3.0 = docFreq 21.0 = docCount
0.49198496 = tfNorm, computed as (freq * (k1 + 1)) / (freq + k1 * (1 - b + b * fieldLength / avgFieldLength))
from: 1.0 = termFreq=1.0 1.2 = parameter k1 0.75 = parameter b 32.285713 = avgFieldLength 113.77778 = fieldLength
In this case, the idf score for the 3 documents turned out to be the same and the tfNorm score is what determined the results in relation to each other. The longer the fieldLength, the lower the tfScore in this case, keeping all the remaining parameters same.






This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.